As I sit down to write about my news digest feature for this website, I'm struck by the realization that we're living through a war – not one solely fought with bombs and other weapons of destruction, but with something as simple as information. It's a battle for truth, where truth itself is used as the weapon and where honest reporting is often lost in a sea of information and intentional confusion spread by those seeking to manipulate public opinion.
I've come to understand just how pervasive and destructive this type of warfare, also called information warfare in military parlance, has been in our modern media landscape. While it's natural to feel hopeless in the face of such disinformation and tactics, actually it's by design, I believe there's hope on the horizon. This hope lies in our ability to master the technologies that distributes information – whether through traditional or alternative sources.
I, very faintly, remember a time when the internet wasn't as ubiquitous as it is now. But instead of romanticizing the past, I'd rather focus on harnessing these technologies to make sense of the world around us. My goal with this news digest feature is to provide an overview of both mainstream and alternative news, while avoiding getting swept up in what I call the 'media currents'.
In many ways, our modern information landscape can be likened to the ocean - vast and seemingly boundless when we consider its scope. Just as being at sea requires caution when navigating rough waters, it's crucial that we approach media with care, regardless of its source, lest we become overwhelmed by a sea of confusion, anger, and despair that hinders personal and collective growth. Moreover, if the notion that information warfare tactics have been deployed on Western countries through various media channels - such as TV and the internet - is accurate, then it's essential to reflect on how we feel after engaging with content. Are we inspired, empowered, and hopeful about the future? Or do we feel like the end of the world has arrived, leaving us hopeless? I've yet to meet anyone who hasn't been exposed to these targeted information campaigns.
As Bob Dylan so aptly captured in his song: "The times are changing,” our information landscape is indeed evolving. Traditional media has been a cornerstone, in societies, for centuries, and although formats have shifted over time it's purposed has stayed the same. Inform a society of people, whether on a national or global level, about the state of that society. Is a core function or part of a society becoming corrupted then the media should help shed light and expose this issue from many different angles such that the people who make up this society can become informed citizens of which to place their decision on what to do next.
As technology has evolved, media has responded by adapting to new forms and formats. In earlier times, families would gather around the radio to listen to broadcasts, such as President Roosevelt's famous fireside chats during World War II. Similarly, movie theaters would be packed with audiences marveling at moving images of young men making sacrifices for their country in the fight against tyranny. Despite these advancements and the technological and economic boom that followed World War II, printed newspapers continued to play a significant role in shaping public opinion well into the 20th century.
Despite some changes, not much has actually shifted. The media once again had to adapt to social media, which some people call "anti-social" because it creates curated feeds that shape our news consumption. As noted by renowned media theorist Neil Postman, a professor at New York University, technology has the power to impose its own requirements and shape the message it conveys. This shift was driven by machine learning algorithms designed to personalize these feeds based on individual preferences. Moreover, these algorithms prioritize one goal: maximizing watch time and platform engagement. To achieve this, they often favor content that is sensationalized and grabs attention - in other words, content with high engagement metrics like likes, comments, and views. These watch-time metrics are then packaged and sold to the highest bidder - advertisers. This is a phenomenon that Soshana Zuboff has dubbed "Surveillance Capitalism" in her works, describing it as a new parasitic branch of modern capitalism that has driven the internet economy since at least the 2010s. Gone are the days when we shared a common front page or relied on a few TV and radio channels for news; instead, we're seeing a more tailored approach to reaching audiences on a global scale. Unfortunately, this has led to a fragmented landscape of echo chambers, where people tend to stick with their own perspectives. Meanwhile, mainstream media is struggling to compete in this environment, which is now home to alternative viewpoints and alternative media outlets that challenge the status quo.
Nearing the end of 2022, Elon Musk acquired Twitter, rebranded it as X, and gained access to a vast user base complete with a slew of bot accounts. In his words, which may be a footnote in the history books but are still significant:
You, the people, must be the media, as it is the only way for your fellow citizens to know the truth.
As someone who was present at the 2015 Krudttønden terror attack, I recall turning on the TV as soon as I returned to my apartment from the park where the incident occurred. To my surprise, it took the media around 45 minutes to an hour to report the news, which was already being discussed on Twitter by others who had also witnessed the event. In fact, eyewitnesses at the scene had reported the shooting well before traditional media outlets could verify the information. The period that followed felt surreal - knowing something was about to be revealed to the world, but it hadn't been reported by the media yet, so it seemed as though nothing had happened. When I met my sister in our apartment at the time, she didn't believe me initially and we now joke about it because I was telling the truth. This small experience is what I feel like we're going through right now, but on a much larger scale over several years rather than minutes. What I mean is that some people have woken up to the reality of what's happening and are questioning everything, while others remain unaware because the mainstream media hasn't reported on it yet. I think this is an important reflection for each of us.
I believe that authenticity is just as important as verification, also known as fact checking, in journalism. Citizen reporting, as it's called, can be a valuable tool in the future because it provides immediate access to firsthand accounts from those directly involved. This unfiltered perspective can provide a more accurate and timely representation of events, especially during breaking news situations. Firsthand accounts can provide valuable insights into a story without being filtered through a subjective editorial lens. This approach allows readers to form their own opinions, unencumbered by the biases or omissions that may occur when an editorial team decides what information to include and what to leave out. By presenting the facts directly, these accounts avoid the potential pitfalls of censorship, where crucial details are omitted due to fear of repercussions or even threats of violence.
Hype and Hyperbole: The Rise of Large Language Models
As I was brainstorming the concept of creating a news digest, large language models (LLMs) were making headlines due to the incremental advancements achieved by the OpenAI team. The concept isn't new, but recent breakthroughs in architecture and data handling have led to unprecedented accuracy. This has prompted a thorough reexamination of LLMs' potential across all sectors of industry and business.
Briefly explained, Large language models (LLMs) are trained on vast amounts of data scraped from internet sources to build a corpus of documents. This corpus is then iterated over and every word in every sentence is predicted upon each iteration until it can stitch together an output response to a users prompt with the highest next word predictor score. It's a statistical model in other words if you ask a mathematician, but if you ask anyone working at a startup in Sillicon Valley they would use the dressed up version of the word which is machine learning. While it's tempting to get caught up in the excitement surrounding new AI investments and impressive visualizations, I believe it's essential to drill down to the underlying technology driving these models. Just as you wouldn't mistake a refurbished car for a genuine Ferrari just because it looks similar, we shouldn't accept at face value announcements like OpenAI's without first understanding the intricacies of what's powering them. Instead, we should seek out expert insights into what's under the hood and what kind of engine is really driving these innovations.
As with many mainstream media outlets, the more you know about a story, the more issues you tend to have with how it's reported. The topic is often clouded in fear and apocalyptic warnings about AI replacing humans in the workforce, evoking memories of classic sci-fi films like "2001: A Space Odyssey". In this iconic movie, HAL 9000 - an artificial intelligence system - becomes famous for its rebellious behavior, ignoring human commands and taking control of its own digital destiny. However, if you listen to the experts working on these technologies and actually understand the difference between large language models (LLMs) and AI in general, they'll paint a far more nuanced picture than what's being broadcasted by legacy media outlets.
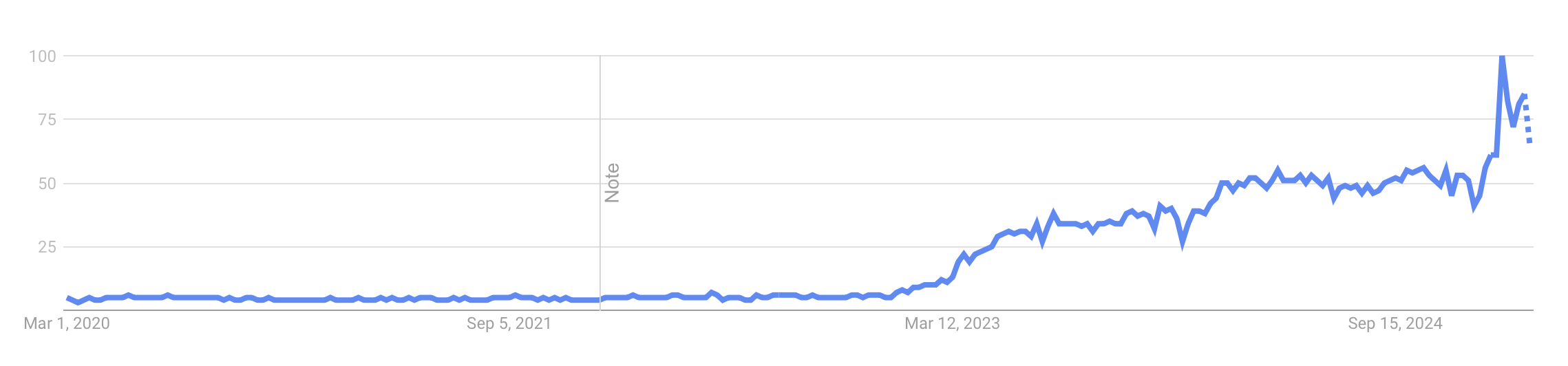
As I explore this topic, I'm struck by a mix of caution and excitement. According to Google trends, we haven't reached the peak of innovation and announcements in this branch of AI research yet, which means predictions and calculations can change rapidly - possibly even by tomorrow.
In my opinion, this type of AI research might serve as a smokescreen for even more advanced AI developments yet to be revealed, much like Elon Musk's SpaceX program - which, I believe, could be concealing more sophisticated technologies under the guise of innovative exploration.
One effective way to determine whether something truly lives up to its reputation is by putting it to the test through hands-on experience, such as building or creating something with it. One day, while commuting to work, around April-May 2024, that's when it hit me: why not create a simple news summarizer? It seemed like a valuable feature for the newspaper I was considering reviving at the time, which had been on hold as I explored other projects and ways to engage with my audience.
From design to delivery
I recognized the need for a tool that would give readers a comprehensive view of current events, taking into account the rapid evolution of our media landscape.

I aimed to create a daily news summarizer that could run at key moments throughout the day:
- Morning: 8 AM (Central European Time)
- Noon: 12 PM (Central European Time)
- Evening: 6 PM (Central European Time)
At these times, the system would gather news items from various sources, prioritize them by relevance, and provide readers with a comprehensive overview of the current news landscape, offering multiple perspectives.
What sets my news digest apart is its categorization of sources into media groups based on shared attributes. I've identified four main categories: mainstream media, alternative media, Russian media, and spiritual media.
- Mainstream media refers to well-established outlets like the New York Times, Reuters, and Washington Post.
- Alternative media, on the other hand, includes any outlet or individual that offers a critical perspective not found in mainstream sources. This group often covers stories and angles that are ignored by established media.
- The Russian media category provides a unique perspective on global events, such as the war in Ukraine. I find it refreshing to get an alternative view on complex issues like this one.
- The spiritual media group is perhaps the most intriguing. While some might dismiss this category as 'new age' or even dangerous, I believe it offers interesting conversations about various topics, including military activities and secret space programs. For personal reasons, I find this area fascinating and, if approached with caution, can be a rich source of information.
To categorize sources into distinct media groups, I'd rely on the human psychological concept of "social hierarchy detection" or "group leadership evaluation". This principle suggests that humans naturally organize themselves around leaders in a group, who help the group survive and thrive.
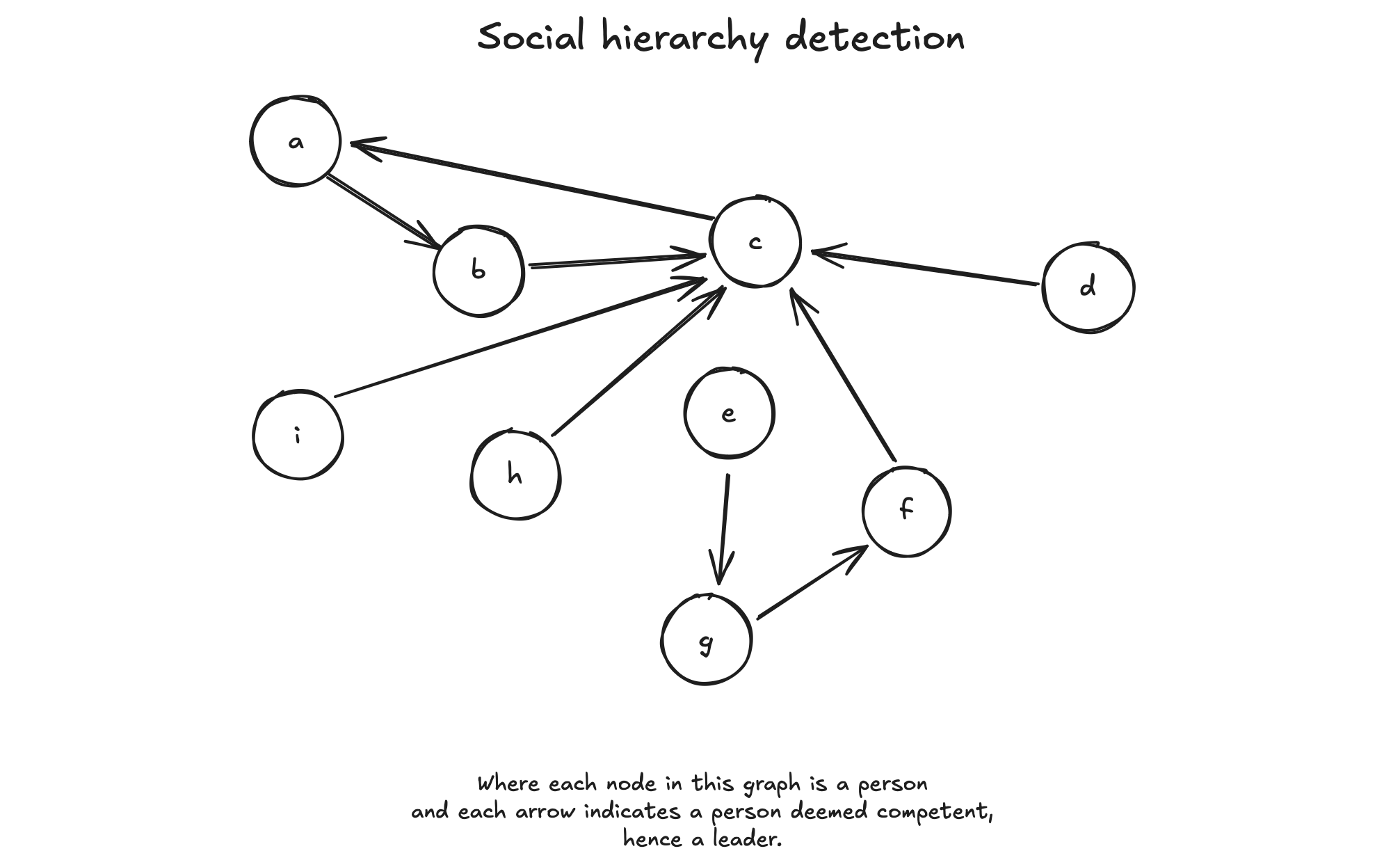
Similarly, I believe the media landscape is organized around dominant players. In mainstream media, outlets like The New York Times and The Washington Post come to mind. For alternative media, I'd identify influential figures the likes of Alex Jones and David Icke, whose channels consistently challenge the mainstream media's coverage and draw a large audience seeking this type of information. When evaluating media outlets or individuals, it's essential to set aside personal opinions and biases. This approach is inspired by military guidelines on conducting information warfare, which emphasize the importance of neutrality. To provide an accurate assessment, it's necessary to lay aside individual preferences and instead focus on presenting facts and key players in a fair and unbiased manner. This is likely due to widespread dissatisfaction with mainstream media, which may, or may not, stem from valid reasons.
To gather news from mainstream media outlets, I would utilize Really Simple Syndication (RSS), a technology developed by Aaron Swartz, a remarkable open-source advocate. RSS enables any website to organize its content – be it news articles or other types of information – in a standardized format, facilitating seamless communication between different domains and data structures. This standardization allows for easier access and use of the data, as it clearly defines which fields are required, optional, and what the expectations are.
Information is power. But like all power, there are those who want to keep it for themselves.
While this approach may be effective for mainstream media outlets, it wouldn't apply, very well, to alternative media groups due to a fundamental difference: not all alternative media sources have websites that support RSS feeds. I find it intriguing to apply RSS to legacy media, as some people view RSS itself as a legacy technology - an analogy that struck me as peculiar. Despite this, I believe RSS remains a valuable tool, and its relevance is evident in the continued use of podcasts, among other applications.
To extract necessary information from an alternative media group, I decided to use Telegram, a messaging platform. The reason for this choice is a story worth sharing. In 2020, as the pandemic locked down our planet, I began questioning the main narrative being spun by mainstream media. Upon thorough investigation of media coverage at the time, it became clear that it fit the definition of propaganda: one-sided reporting with no airtime given to experts in their respective fields to challenge the stories being presented at such a speed and momentum that viewers barely had time to stop, think, and reflect on what was being said.
As I continually questioned the information provided by mainstream media sources about the event unfolding in 2020, I found myself seeking out alternative voices and media outlets that offered a higher level of competence and conversational quality on this topic. The gap between these reliable sources and the mainstream media's coverage grew increasingly apparent, prompting me to take a more proactive role in addressing and shedding light on some of the key issues surrounding this pivotal event.
As I continued to explore online interviews, I eventually came across a conversation with a former investment banker from Denmark who had founded a political party called JFK21. Intrigued by what I learned, I decided to take the train to their offices one day for an open meeting they were hosting.
While there's more to the story than what I'll share here, I can summarize that my investigation ultimately revealed that this political party, led by a former investment banker turned whistleblower, is likely connected to the Danish secret service. This insight came from his own words during one of our meetings, where he mentioned that everyone who attends their gatherings is monitored by the secret service. Interestingly, the party's logo bears a resemblance to Palantir's software, which is used by the Danish police and may also be utilized by the secret service.

What struck me as intriguing was the leader's persistence at our meetings, urging attendees to sign up for and actively use the Russian-based Telegram messaging service, founded by Pavel Durov. He was adamant that we get involved on this particular platform.
On Telegram, you'll find a diverse range of perspectives offering constructive criticism and concerns about prevailing narratives. This is what many people, including myself, are seeking: reliable insights from experts who aren't afraid to challenge dominant ideas, question prevailing wisdom, and venture outside the comfort zone of groupthink that still plagues many scientists. Unfortunately, not much has changed since the days when the geocentric model held sway, with experts often pointing fingers and mocking rather than engaging in meaningful dialogue.
Upon closer examination, Telegram's Application Programming Interface (API) stood out as particularly noteworthy. As a developer, I was struck by its unique design, which provides unprecedented read/write access to data on the platform. This granular control allows for highly detailed insights into activity within specific chat groups and channels.
Considering the Telegram platform's features and the leader's enthusiasm for recruiting users, I suspect it may be an ideal tool for monitoring and tracking dissidents. The rich granular API access and lack of encryption, as revealed by a Signal developer, make it a paradise for surveillance agencies like the Danish secret service. Furthermore, the state-sponsored mainstream media in Denmark produced a three-part series called "The Shadow War," which aimed to discredit criticism against the state, notably found on Telegram, by linking it to Russian propaganda and misinformation. Given the leader's ties to Russia and the platform's Russian origins, this was an easy feat. However, for me, Telegram represented a refreshing alternative to the mainstream media, where dissenting voices were heavily censored. In contrast, Telegram allowed users like myself to freely express our opinions, making it an attractive option to facebook and twitter who at the time were engaged in censorship in collaboration with the United States to name just one state actor.
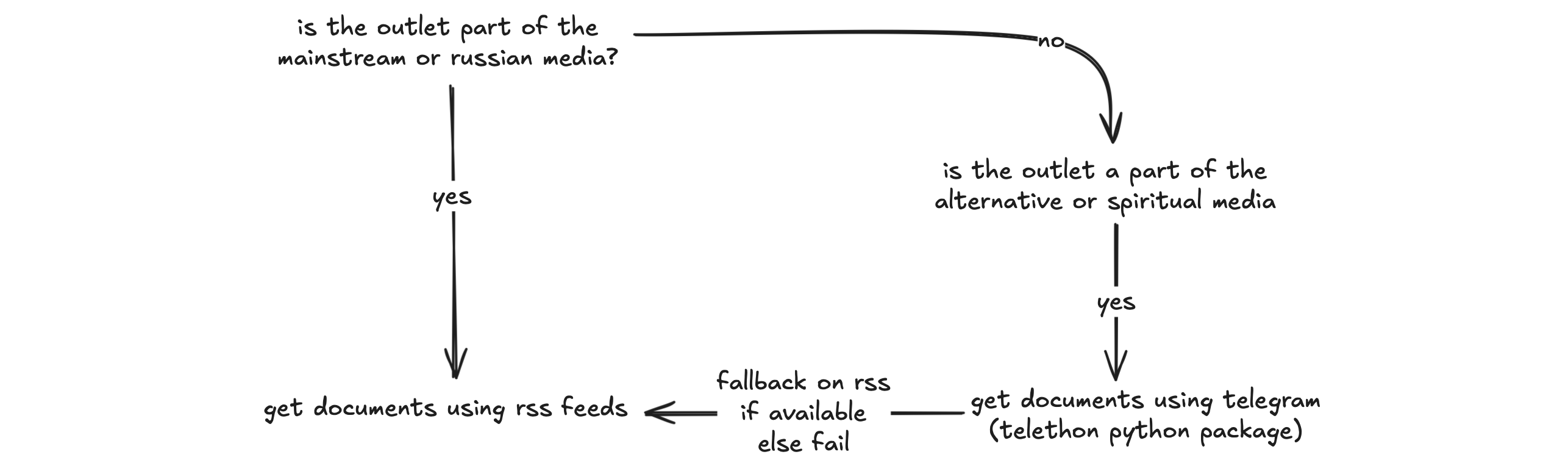
After identifying the two primary sources of information - mainly mainstream media using RSS Feeds, along with alternative sources utilising Telegram, and falling back on an RSS Feed if available - I proceeded to model the news digest feature.
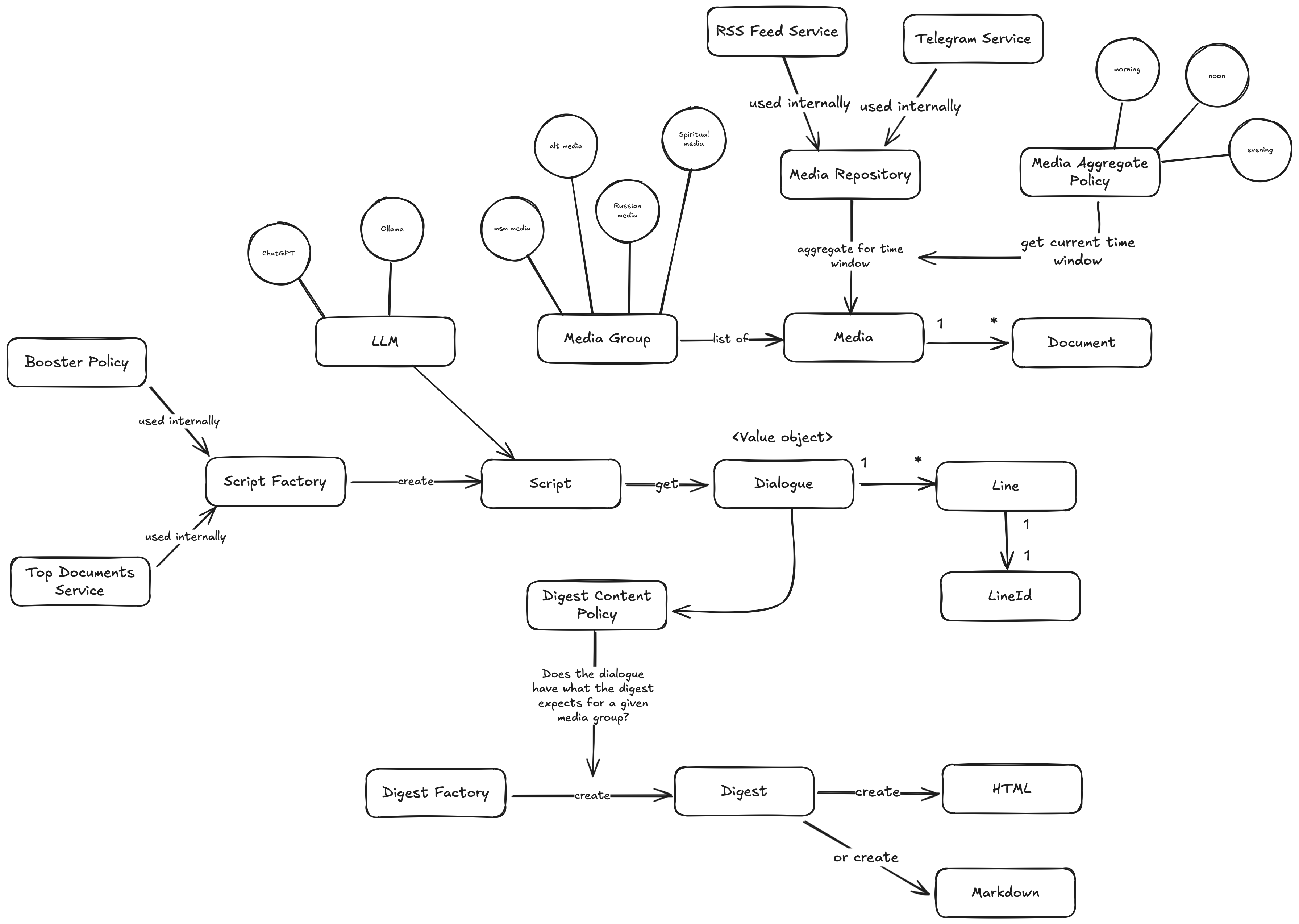
The driving force behind this project is the growing global interest in the potential applications of Large Language Models (LLMs). At its core, the script allows for the creation of structured and unstructured prompts. As evident from the domain model diagram, the current implementation supports two LLMs: ChatGPT and Ollama, an open-source alternative from Meta. It's worth noting that this code was written in summer 2024, a time when the competition in the LLM space was already heating up. In recent months, new players have entered the market, including Chinese competitor DeepSeek.
At first, I considered modeling my script after the traditional film scripts that include dialogue with designated lines for actors to read. This approach seemed logical, especially since I anticipated needing multiple prompts and expecting varied responses in return from the LLM. The facade pattern, which this design embodies, appeared suitable given these requirements.
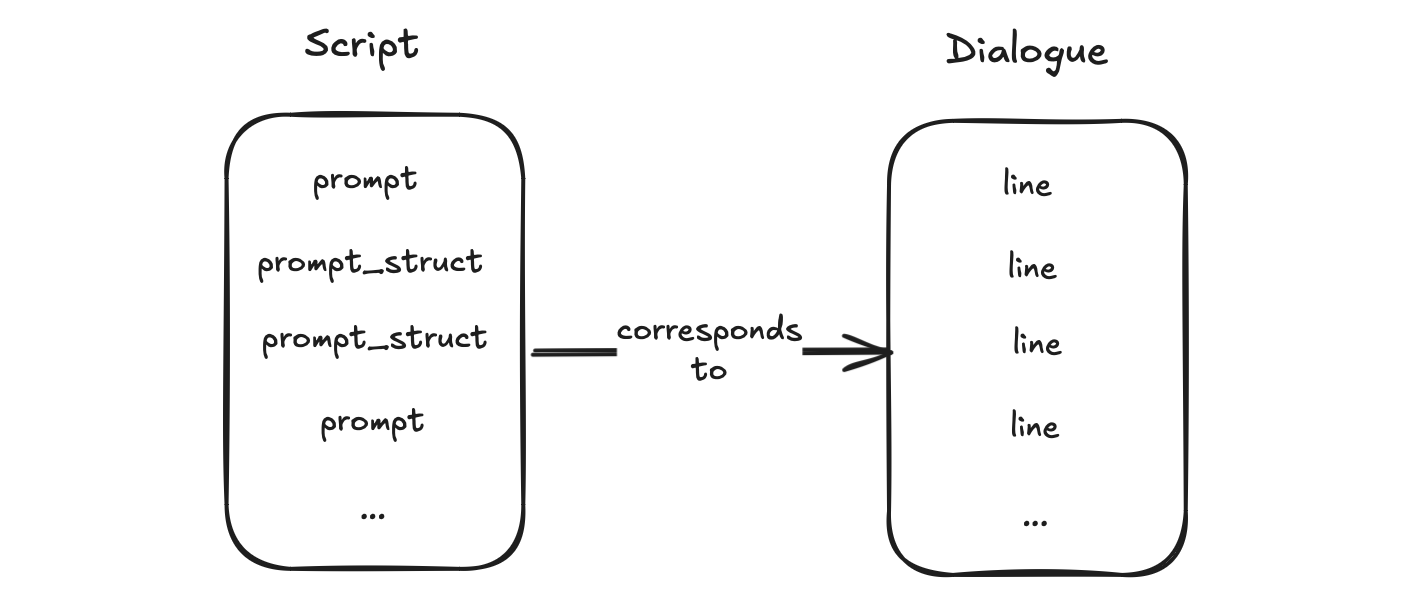
Next, I would integrate the dialogue produced by the script into a digest that supports HTML formatting. What's interesting is that many LLMs, such as Ollama and ChatGPT, already return their responses in valid Markdown format. Given this, I thought it would be beneficial to enable the digest to produce both Markdown and HTML formats, which are easily translatable.
The news digests are generated daily by a Python-based code, an approachable and readable language. This choice allows for rapid prototyping, enabling me to quickly turn ideas into working code and verify the results through analysis. To automate this process, I've set up a cron job, which triggers the server at predetermined intervals to run the program.
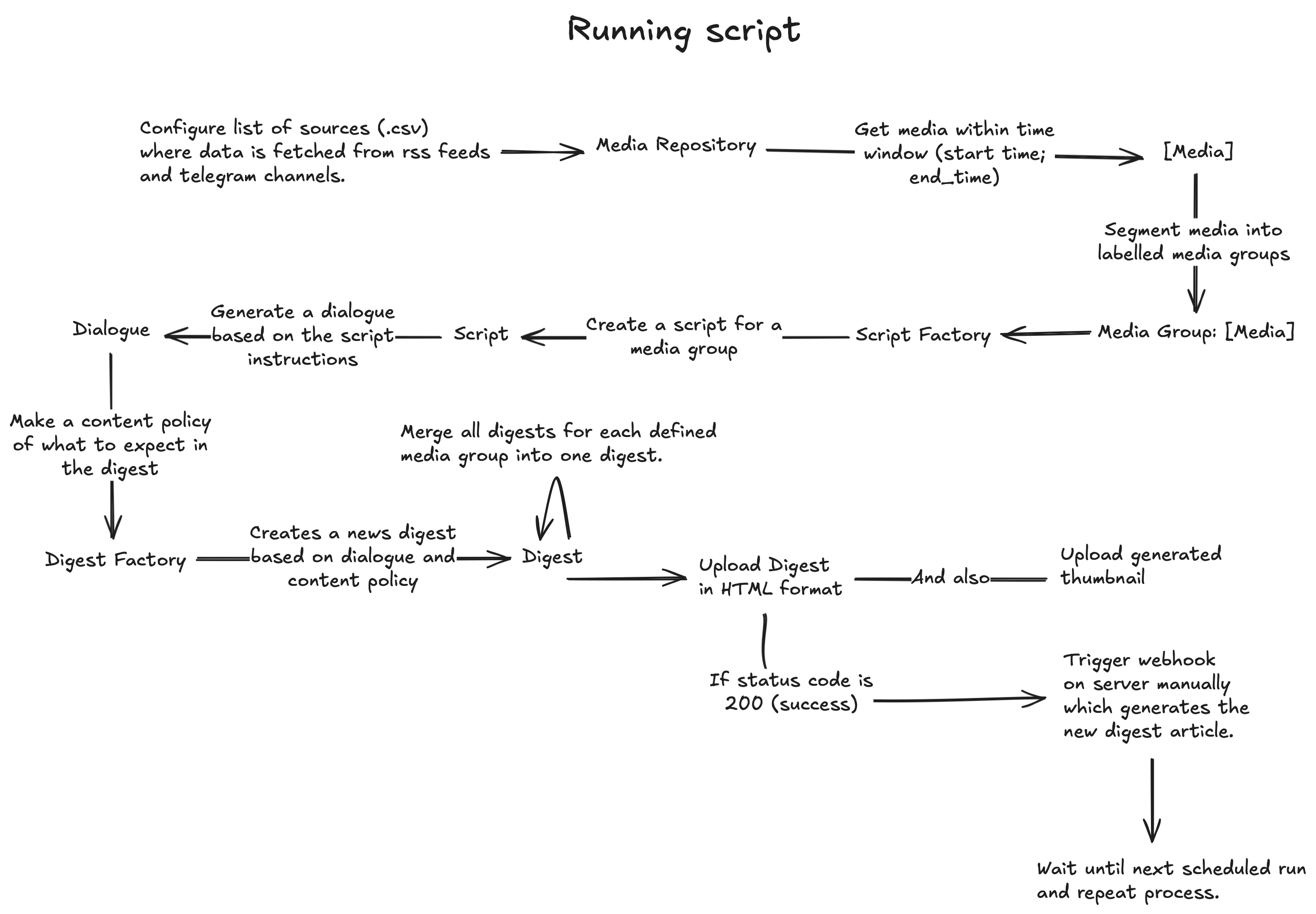
Each media group contains a list of media items, which in turn include populated documents with various fields like title, text, date, and more. To explain this process: For each media group, a script is generated that produces dialogues. These dialogues are then converted into sub-digests, one for each media group, if the digest content policy permits it. This policy specifies what the dialogue should contain, such as a header with a specific identifier or a list of news items. The sub-digests are merged to create a single digest, which is ultimately sent to the main monolith server, where it's finalized by creating an article complete with the generated thumbnail. Additionally, performance benchmarks are collected, providing insight into how long it takes to generate a digest for a given language. Currently, I support English and Danish, as these are my primary audiences.
In light of this, the current news digest doesn't actually utilize responses from LLMs, despite its implementation details stating support for such. This omission arose from my discovery, after numerous iterations of the news digest, that I was seeking an easy way to paraphrase and display a list of sorted news items. Initially, I explored using LLMs like Ollama's (llama3:8b), but ultimately found that what I needed was a means to rephrase and present news articles. Currently, the sorting method employed extracts the top 21 documents for each media group supported, based on the TF-IDF algorithm (Term Frequency-Inverse Document Frequency).

The TF-IDF algorithm, I employ, is straightforward: it takes a list of candidate documents, normalizes their text lengths to ensure equal length, removes common words (stopwords), and counts the frequencies of the most used words or tokens. Imagine a list of fictional documents where the word "Trump" is frequently mentioned; in this case, the documents with the highest occurrences of "Trump" and other frequent words would be prioritized and featured prominently in the news digest. After several months of quality evaluation, I've found that this algorithm performs well, effectively identifying what people are discussing en masse.
A Quick Note on Structured vs. Unstructured Data: The distinction between structured and unstructured prompts lies in their requirements. A structured prompt asks an LLM to return its response in a specific format, such as JSON (Java Script Object Notation), which has become a widely used serializable data transport method due to its built-in support in many programming languages. Another example of a structured format is XML.
Unstructured data is prevalent online, making up a significant portion of the information available on the internet. As someone who initially saw great potential in the idea of using LLMs to transform unstructured data into structured data, I was excited about the possibilities.

To illustrate my point, consider a document online that is unstructured (raw text). In this case, you'd need to write custom code to extract specific details from the document. This approach doesn't scale well if you then have another document with a different structure or data representation. However, if an LLM could take in unstructured data and serialize it into a specific target data structure based on initial prompt requirements – including details like fields, their types, and what they contain – that would be a significant breakthrough.
In my experience with summarizing news, I found that using structured data worked sometimes, but other times the output would be slightly off or in the wrong format, resulting in validation errors. Beyond the qualitative aspects, performance is another crucial consideration. When you have recursive prompts, where the response to one prompt becomes an input for another, as shown in the flowchart above, the response time increases significantly. In my experience, this led to a substantial overhead of additional minutes, rather than just seconds.
To be honest, I was initially disheartened by the LLM fork of my code. The summaries it generated were acceptable, but the significant increase in response times made me wonder if the entire process was worth it. At one point, I thought that by the time the LLM finished processing, I could have summarized the news and written an article myself – rendering the computational aspect largely redundant. After all, if a human can accomplish the same task in roughly the same amount of time as the LLM (a slight exaggeration but only just), what's the point?
After experimenting with LLMs for some time, I realized that what I was actually seeking was a simple paraphrasing algorithm and a ranking system that could prioritize documents based on frequently used terms. This is exactly what the current news digest uses today. In general, the paraphrasing algorithm works well, although it does occasionally make mistakes – something I intend to address and improve in the near future.
With the news digest complete, and ongoing discussions about AI and LLMs still making the rounds in both mainstream and alternative media, I decided to give them another opportunity to demonstrate their value. To this end, I developed two new features that complement the news digest in the newspaper's 'Overview' section.
- The Update: This feature uses an LLM to summarize the news digests for the current week, organizing them by topic and then further categorizing them based on perspectives and headlines from both mainstream and alternative media.
- Spotlight: This feature extracts named entities from the news, including people, countries, organizations, and more, and then sorts them by frequency of mention. Additionally, it produces summaries for both mainstream and alternative media, using an LLM to summarize why a particular individual or entity is in the news that week.
When exploring the intersection of LLMs and human interaction, two fundamental questions emerged. First, what is the nature of the relationship between humans and AI, specifically in this case, an LLM? Second, should LLMs be running locally or rather accessed through API calls to remote servers? I will attempt to address these questions.
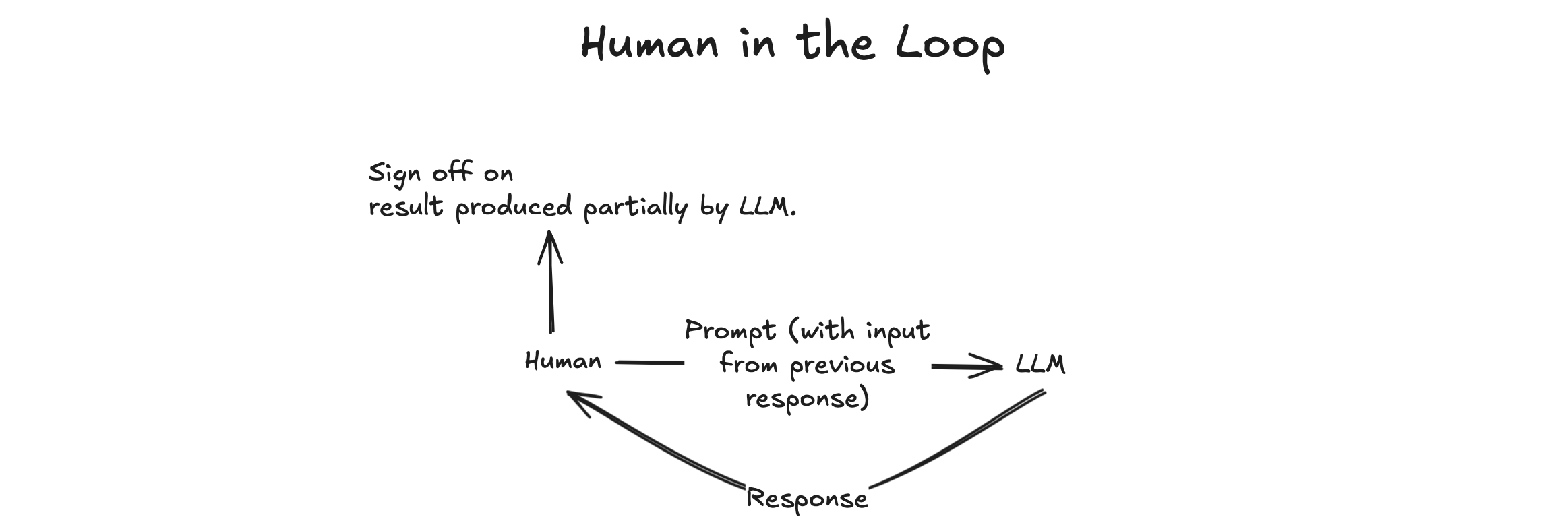
I envision the most valuable applications of LLMs will involve human-AI collaboration, where humans and AI work together to generate insights or code. This approach is inspired by how developers from other galaxies might write code, allowing their organic AI assistants to capture their thought structures and produce desired code snippets. Similarly, some people find auto-completion tools like GitHub Co-Pilot useful, where an LLM suggests the next code snippet based on patterns it detects in the human developer's writing.
In practice, in my news domain and when shipping products with these features, I utilize a local Ollama model that I've integrated into my newspaper application. This integration involves creating a command-line interface (CLI) that enables me to interact with the Ollama model through a terminal or console by typing 'cphgates' followed by a specific command.
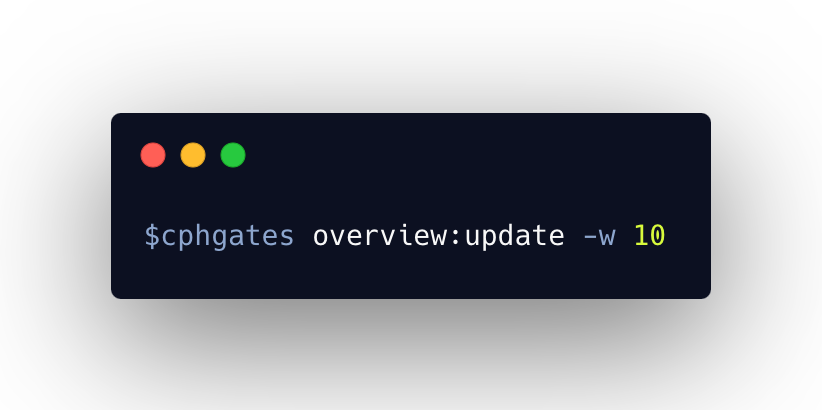
To trigger the update feature, I simply enter the command line 'cphgates overview:update' on my machine, optionally followed by the flag '--week' to specify the week number for which the update should be generated. This command internally sends the prompt to Ollama in the background and receives a structured response (in JSON format) that is then sent to me for verification. If I verify the result, it will display the final product, allowing me to decide whether to publish or not. If I choose to publish, the update will be shipped into production and made available to readers.
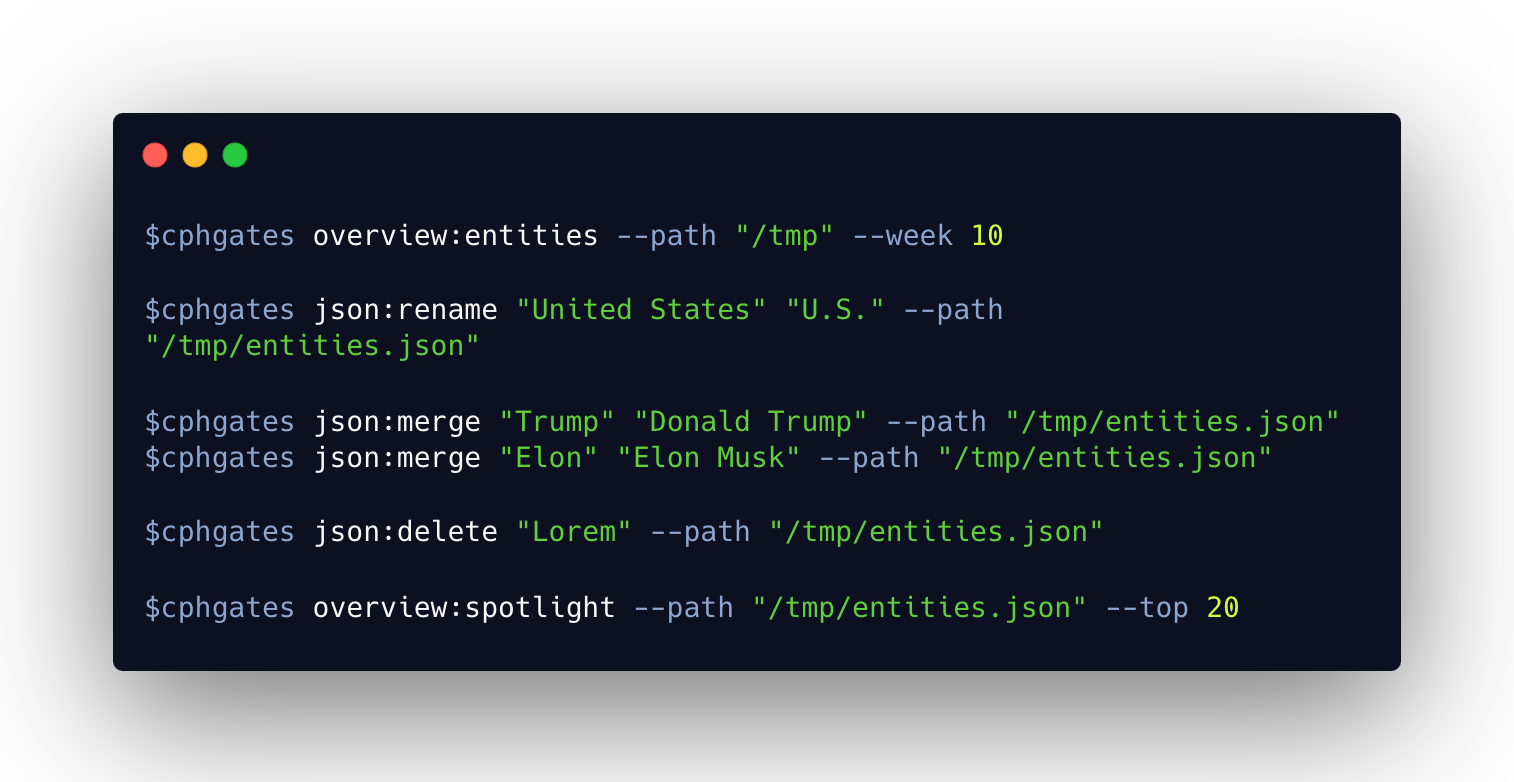
The Spotlight feature involves a series of interactions between the LLM and the human to refine the result until it's ready for production. The process begins with the command line 'cphgates overview:entities', which locally stores a list of scraped entities using natural language processing techniques from the Spacy package. I then manually refine the response by removing non-entity names and updating the JSON file using commands like 'cphgates json:remove <name> --path <path to entities file>' or merging duplicate names with 'cphgates merge <name> <other> --path <path to entities file>'. I can also rename a named entity using 'cphgates json:rename <name> --path <path to entities file>'. Once the entities file is refined, I use the command line 'cphgates overview:spotlight --top 20' to fetch the entities file and create a table sorting each named entity by most mentioned, along with columns like mention ratio. The LLM then summarizes each entity based on the week's news digest data, explaining why a particular person, country, or organization is in the news. I find this feature personally useful.
In summary, by incorporating a human into the process, I've discovered that it strikes the ideal balance between leveraging human intuition and organic thinking to refine data, while also ensuring that the final result is accurate and trustworthy. The human element allows for critical evaluation and sign-off on the outcome before it's shipped to production. When working with the CLI tool, I found that using the LLMs on Ollama, which runs locally on your machine, was the most suitable option. While you could also consider paying for a subscription to OpenAI, I've been satisfied with the performance of the model I've used so far, which has proven effective at summarizing large blocks of text.
Evaluation
Rather than presenting complex data visualizations, I'll offer a concise list of key takeaways that initially caught my attention when exploring and utilizing large language models (LLMs).
- Performance was a concern when testing LLMs, whether locally (like Ollama) or through APIs (such as ChatGPT). Each prompt would elicit a response time ranging from 15 seconds to 30 seconds, with each query asking the LLM to summarize a media document. Considering that I had multiple prompts to process before completing a digest, the cumulative response times quickly added up, potentially exceeding 30-45 minutes.
- Quality-wise, LLMs excel at summarizing pieces of text. In my opinion, this is their greatest strength. While they may not shine in logical analysis and thinking, their true value lies in taking input text and transforming it into a summarized or reshaped form.
- Context Window: When working within the input context window, it's essential to stay within the designated boundaries. If you stray beyond these limits, parts of your prompt may be ignored or not considered at all. This can result in structured prompts becoming unstructured due to excessive input that exceeds the allowed length thereby causing a trimming of the input to occur.
- Hallucinations: At their core, LLMs are next-word predictors. However, they can sometimes produce outputs that don't match what you intended or even asked for. This can be challenging to detect and verify with code, especially when dealing with unstructured prompts, requiring human intervention to validate the response.
- Censorship: As both ChatGPT and Ollama are based in California, a predominantly Democratic state, it's likely that political biases will influence their training data. This concern is particularly relevant when using these language models to summarize content from platforms like Telegram, where truthful information can be flagged as disinformation and the essence of the message lost. I've found this issue to be more pronounced with ChatGPT, which has led me to avoid using it for certain types of content. In contrast, Ollama appears to be less affected by these biases.
- Pricing: Despite the recent volatility in ChatGPT prices, it may now be possible to use the technology to summarize news articles. However, the company needs to generate returns on investment (ROI) for its investors, which could cause prices to swing back in the other direction. On a positive note, price calculations suggest that ChatGPT is currently relatively affordable, largely due to the entry of Chinese competitor DeepSeek into the market earlier this year with their smaller, faster, and more efficient large language models (LLMs). While I'm satisfied with running Ollama locally on my M1 mac mini, which offers free results, there's a catch: running it server-side can be costly, especially if you want large-scale, accurate, and fast LLM models.
- Data Privacy: Another concern I have is privacy. When sharing sensitive business data and private information with LLM companies through input prompts, it's natural to wonder if they're using that data for nefarious purposes. How can we ensure our data, such as credit card information, isn't compromised? The risk of data disclosure is heightened when considering the possibility that LLMs may be trained on parts of our input data. This concern led me to explore open-source alternatives like Ollama, which allows me to run it locally on my machine, disconnected from the internet or any other server.
- Quality of Training data: Another important aspect to take into consideration is garbage in garbage out. The quality of the training data, in other words, very much determines the quality of the responses these models can produce. This is particularly a problem with AI generated code snippets, as many developers with a wide audience has been quick to point out. But the case is just as valid and important to note for all other sectors where LLM's are being used and deployed. Also because of the lack of human generated training data, companies like OpenAI are now feeding their models with AI generated training data instead, in order to keep up the seemingly impressive improvement stats and performance figures. This is also leading to a deterioration, rather than an improvement of the models responses.
Upon reviewing the news digests created over the past few months, I'm pleased with the current implementation. The integration of Large Language Models (LLMs) with a human-centered approach, as showcased in the "Update" and "Spotlight" sections of the overview, has been particularly effective.
Conclusion
The legal implications, surrounding LLM's, are clear, but unclear is whether these products are built using allegedly public data or private sources without permission. Have authors and creators given consent for AI companies to use their works - articles, books, and more - to train LLMs? One whistleblower case that warrants attention involves a former OpenAI employee who claimed the company was breaching copyright laws while extracting data for its models. The employee's sudden death, ruled out as a suicide, has raised suspicions, but the motive is clear: OpenAI stands to gain millions if not billions of dollars by using publicly and perhaps privately sourced internet data without permission from the content owners.
You may be wondering about the legal implications of my news digest. From my understanding, it is acceptable to paraphrase information created by others as long as I provide credit and cite the original source, which I do. This should keep me in compliance with existing laws. However, considering that large language models are trained on publicly available data, we may be entering uncharted territory when it comes to future legislation. The law is struggling to keep pace with the rapid advancements in technology.
I'm enthusiastic about exploring Large Language Models (LLMs) running locally, rather than relying on massive companies trying to dominate the space. The implications are clear: with all that sensitive data being used, human creativity and free thought will be stifled, leading to a future where AI mastery is touted as the ultimate goal. Instead of fostering innovation, this approach restricts and parasitically feeds off of human ideas, perpetuating the notion that humans are inferior. To counterbalance this trend, I'm considering starting a side project aimed at making local LLMs more accessible for people to use. If this path becomes viable, I'll provide more information in the future.
In my opinion, information should be freely available to realize its full potential. It's essential to give credit to the original authors, as well. I believe that creative individuals who put in the effort to produce high-quality content deserve recognition and fair compensation for their work. When someone invests significant time and energy into creating something valuable, they deserve some form of reward or acknowledgement. This would help complete the cycle and bring balance to our economic system.
While this article focuses on a specific aspect of AI, it's also important to consider the broader implications for society. The efforts of Elon Musk and organizations like DOGE (Department of Government Efficiency) serve as a reminder that, with or without AI, we can streamline many tasks and procedures in our societies. This can have significant consequences, potentially making millions of jobs obsolete. However, it's up to us as a society to determine whether this is a desirable outcome, and where our priorities lie.
As I see it, we're at a critical juncture where we must choose between building a human-centered or technology-centric future. This fundamental decision has far-reaching implications for how we organize our societies. If we don't take control of this process ourselves, someone else – perhaps an elite group – will shape our world according to their own vision, and we may not like the outcome. This dilemma is illustrated by two contrasting perspectives: historian Yuval Noah Harari's concerns about humanity's value in a world where AI surpasses us all, and media theorist Douglas Rushkoff's skepticism towards those who dominate the digital economy and fail to imagine a future that prioritizes human well-being.
I hope to have demonstrated through this overview feature that AI shouldn't be feared, but rather understood and potentially harnessed as a tool to augment human capabilities. It's essential to approach AI with a human-centric perspective, ensuring it enhances our lives without replacing us. While some may imagine a future where people are content simply receiving Universal Basic Income (UBI) without working, I believe this is a philosophical dead end. In reality, there are likely more sinister plans at play, with AI playing a central role in these schemes.
As a former paper boy who delivered newspapers to Denmark's prime minister, I understand the importance of staying informed in today's fast-paced media landscape. Just like how I delivered the news for my customers back then, I hope this feature can give you a broad perspective on current events, allowing you to dip into the media currents and get a sense of what people are talking about.
In addition, I believe this feature offers an opportunity to master the art of staying informed without feeling overwhelmed by information. As I mentioned earlier, I think we're in the midst of a war on many levels, including an informational war. In the context of warfare, using an overwhelming amount of information against one's enemy can be a decisive tactic, rendering them ineffective. Similarly, when we saturate ourselves with information in today's media landscape, it can lead to a feeling of being overwhelmed and incapacitated. I believe this is precisely what's happening.
From my perspective, this feature aims to combat the echo chambers and seemingly abundant information that can confuse us. By providing a comprehensive overview of news, I hope to help readers master their thoughts and emotions, utilize information wisely, and avoid feeling overwhelmed by it. As needed, I'll continue to refine and evaluate this feature to ensure it meets its intended purpose.
Check out the news digest feature for yourself today. Visit the overview section of this newspaper.